

Capítulo 7 de la serie Sprint DGX (desde el Capítulo 1). El bench que valida el VLM entrenado como servicio realmente deployable.
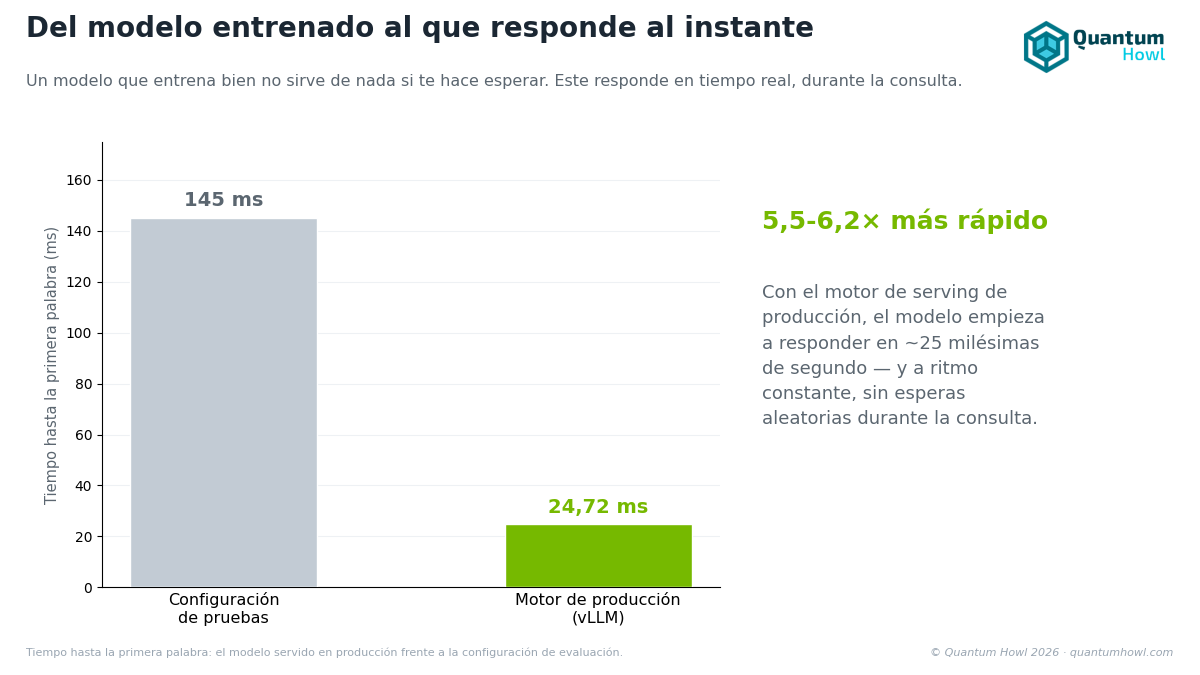
Entrenar bien un modelo y poder servirlo en consulta son dos problemas distintos. Un checkpoint que aprende es solo eso: pesos en disco. Para que un dentista lo use durante la visita hace falta que responda al instante y mantenga la latencia estable bajo carga, incluso en los picos de uso, sin tropezar. Este capítulo cuenta el salto del laboratorio al servicio: un barrido de quince configuraciones de vLLM que lleva el tiempo hasta el primer token de los ~140 ms iniciales a 24,72 ms, entre 5,5 y 6,2 veces más rápido, con una cola de latencia tan estrecha (por debajo de 1 ms entre la mediana y el percentil 99) que la espera es prácticamente idéntica en cada llamada. Y, como prueba de fuego, la primera mirada del modelo a una radiografía real a través del runtime de serving del entregable.
El gap entre training y serving
La utilidad de inference que trae el framework de training está optimizada para evaluar checkpoints durante el entrenamiento. No es un servicio. Tiene tres limitaciones operacionales para producción:
- Sin KV cache compartido entre peticiones, cada llamada arranca desde cero.
- Sin batching dinámico, las peticiones concurrentes se serializan.
- Sin API OpenAI-compatible, requiere un cliente Python a medida, no se integra con el SDK que usa el resto del producto.
Los números iniciales, medidos con esa utilidad, son honestos pero no útiles para deploy:
| Métrica baseline (utilidad de training, H100 BF16) | Valor |
|---|---|
| TTFT (time-to-first-token) | 136-153 ms |
| Throughput batch 1 | 12-14 tok/s |
| Throughput batch 4 | 38-40 tok/s |
| VRAM | Holgada, cabe en la GPU |
Para servir el VLM a una clínica hace falta un runtime de serving de verdad: batching dinámico, KV cache reutilizable, scheduler de peticiones concurrentes y una API estable. Evaluamos varias opciones, y la que mejor encajó con Gemma 4, sin sacrificar precisión ni añadir complejidad, fue vLLM, que justo había estrenado soporte para el modelo.
vLLM con soporte Day-0 de Gemma 4
vLLM publicó soporte oficial Day-0 del model_type gemma4. Eso nos dio justo lo que necesitábamos: un runtime de serving que entendía Gemma 4 31B desde el primer día, sin esperar a que el resto del ecosistema se pusiera al día.
Instalar vLLM en el entorno del sprint fue limpio: out-of-the-box, sin build-from-source ni downgrades, sobre el mismo torch y transformers que ya teníamos. Verificado con un dry-run antes de ejecutar nada.
La arquitectura de serving es deliberadamente simple: un único proceso de vLLM sirviendo el modelo en BF16 con paralelismo de tensor sobre dos GPUs, y un endpoint OpenAI-compatible por delante. Cualquier cliente que hable la API de OpenAI conecta directamente. El cliente del producto QuantumHowl ya la habla por defecto, cero adaptación.
El bench sweep
El barrido cubre cuatro dimensiones del espacio de configuración para un load testing representativo de producción:
| Tipo de config | Variantes | n |
|---|---|---|
| Solo texto | 3 longitudes de prompt {128, 512, 2048} × 4 concurrencias {1, 4, 16, 64} | 12 |
| Conversación real (ShareGPT) | batch 1 (100 conversaciones) + batch 4 (100 conversaciones) | 2 |
| Multimodal | entrada de visión + generación de texto | 1 |
El barrido completo corrió en poco más de media hora, con 14 de 15 configuraciones con éxito. La única que falló fue la multimodal, por un conflicto de inicialización del engine al correr en paralelo con el vllm serve ya levantado, no es un blocker: el smoke multimodal se validó por separado (siguiente sección).
Los headline numbers
| Métrica | vLLM BF16, H100 | Baseline (utilidad de training) | Mejora |
|---|---|---|---|
| TTFT p50 | 24,72 ms | 136-153 ms | 5,5-6,2× |
| TTFT p99 | 25,4 ms | ||
| Variance TTFT p50→p99 | < 1 ms | tail estrecho | |
| Throughput batch 1, prompt 128 | 71,12 tok/s | 12-14 tok/s | 5,1-5,9× |
| Throughput batch 4, prompt 128 | 219 tok/s | 38-40 tok/s | 5,5-5,8× |
| Throughput agregado batch 16, prompt 2048 | 549 tok/s | ||
| ShareGPT batch 1 (conversación real) | 100/100 éxito | ||
| ShareGPT batch 4 (conversación real) | 100/100 éxito |
La variance de TTFT entre p50 y p99 por debajo de 1 ms es la firma operacional que de verdad importa. Una mejora de 5,5× en el TTFT mediano se pierde si la cola de latencia es alta, un usuario clínico que unas veces espera 25 ms y otras 250 ms tiene una experiencia inestable. Un tail estrecho indica que el scheduler de vLLM mantiene latencia consistente bajo carga, no solo en el caso medio.
Los 549 tok/s agregados en batch 16 con prompts largos escalan el throughput unas 7,7× respecto a batch 1 cuando el batching dinámico está bien afinado, y eso da holgura de sobra para servir la carga de una clínica con latencia estable incluso en los picos de uso.
Smoke test multimodal: la primera mirada del modelo a una radiografía real
Validación cualitativa sobre una panorámica real con restauraciones anotadas:
| Métrica | Valor |
|---|---|
| Throughput | 42,4 tok/s batch 1 |
| Tokens de prompt | 301 (256 de visión + 45 de texto) |
| Tokens generados | 256 |
| Latencia end-to-end | 6,04 s |
| Idioma de la respuesta | Español |
| Coherencia clínica | Verificada a mano |
La respuesta describe correctamente las restauraciones visibles en la panorámica, identifica las regiones FDI relevantes y mantiene un tono clínico apropiado en español. No es una evaluación deploy-grade (n=1, cualitativa), pero confirma que el pipeline de principio a fin, training (Cap 4) → serving → inferencia multimodal, funciona sobre datos reales, no solo sobre el benchmark.
El camino de producción queda elegido
vLLM con su API OpenAI-compatible es el runtime de serving del entregable: rápido, estable bajo carga y validado de principio a fin sobre el modelo entrenado. La pieza clave es que el cliente del producto QuantumHowl ya habla esa API de forma nativa, así que servir el nuevo VLM no exige ningún cambio de arquitectura, solo apuntar a un endpoint nuevo.
Estado al cerrar esta fase
- vLLM BF16 validado como serving primario.
- Bench sweep documentado: 14 de 15 configuraciones con éxito.
- Headline numbers cerrados: TTFT p50 24,72 ms (5,5-6,2× mejor), 71,12 tok/s en batch 1, 549 tok/s agregados, variance p50-p99 < 1 ms.
- Smoke multimodal validado sobre una panorámica real.
- Camino de producción definido: REST OpenAI-compatible, sin cambios de arquitectura en el cliente.
Próximo capítulo: por qué la DGX Spark importa como objetivo de deploy on-prem por clínica, y cómo encaja el VLM entrenado en sus 128 GB de memoria unificada para correr a precisión completa, dentro del edificio, sin que ninguna imagen del paciente salga a la nube.



