
Capítulo 5 de la serie Sprint DGX (desde el Capítulo 1). Por qué construir benchmarks propios cuando el público no cubre tu distribución real, y qué pasa cuando lo haces.
Un modelo puede sacar buena nota en un examen y aun así no servir para tu clínica. El benchmark dental de referencia, MMOral-Bench, está bien hecho, pero tiene dos sesgos que para nosotros importan: sus 100 imágenes son todas panorámicas, y en consulta llegan también periapicales e intraorales, y está íntegramente en inglés, cuando nuestras clínicas operan en español. Así que en lugar de fiarnos del examen prestado nos fabricamos los nuestros: dos probes propios, panorámico e intraoral, traducidos al español con revisión clínica. Lo que medimos refuta una hipótesis cómoda (que el español «ya venía de fábrica» en Gemma 4) y destapa un hallazgo que no esperábamos: el mejor modelo en inglés no es el mejor en español. La consecuencia es muy práctica para decidir qué versión desplegar en cada mercado.
Por qué construir probes propios
MMOral-Bench (NeurIPS ’25) es un benchmark serio, pero tiene tres limitaciones desde nuestro punto de vista:
- Modalidad única: 100 imágenes, todas panorámicas OPG. El producto real recibe periapicales (frecuentes en la consulta diaria) e intraorales (fotos directas de boca para seguimientos). Ninguna de las dos está en MMOral.
- Idioma único: el benchmark está en inglés. La clínica real opera en español. La paridad ES↔EN del modelo es una hipótesis que hay que validar empíricamente, no asumir.
- n moderado: 491 preguntas cerradas bastan para un McNemar pareado entre modelos, pero el desglose por categoría sufre, muchas quedan con n < 30, con intervalos de confianza anchos y poco interpretables.
Para cubrir ese hueco diseñamos dos probes propios:
| Probe | Dataset origen | Modalidad | n preguntas |
|---|---|---|---|
| panorámico-ES | Dataset panorámico externo | Panorámica OPG | 50 |
| intraoral-ES | Dataset intraoral externo | Intraoral / periapical | 75 |
Las preguntas se construyen sobre imágenes con anotación verificada del dataset original y se traducen al español con un pipeline propio: un modelo de lenguaje traduce, un bucle de revisión repasa la terminología clínica y un filtro automático contrasta contra un glosario dental en español. El resultado son 125 preguntas paralelas ES/EN, listas para evaluar cualquier variante del modelo.
El bloque experimental
La evaluación corrió en cuatro procesos paralelos de dos GPUs cada uno, con panorámico e intraoral en secuencia dentro de cada proceso. En total, unos minutos de cómputo para evaluar 5 modelos × 2 probes × ~125 preguntas.
Modelos evaluados:
- Gemma 4 31B-IT base (sin fine-tune, control)
- Stage 3 SFT v0 (la salida del Cap 4)
- Stage 3b v1 (+panorámico)
- Stage 3b v2 (+intraoral)
- Stage 3b v3 (combinado panorámico + intraoral)
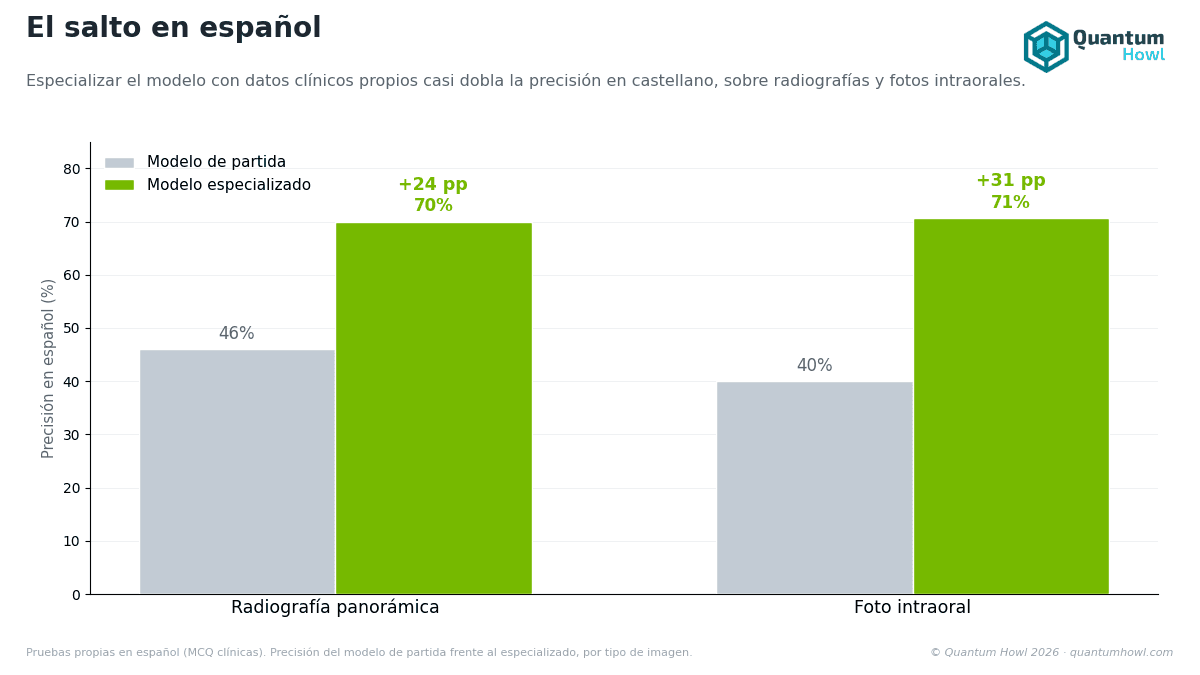
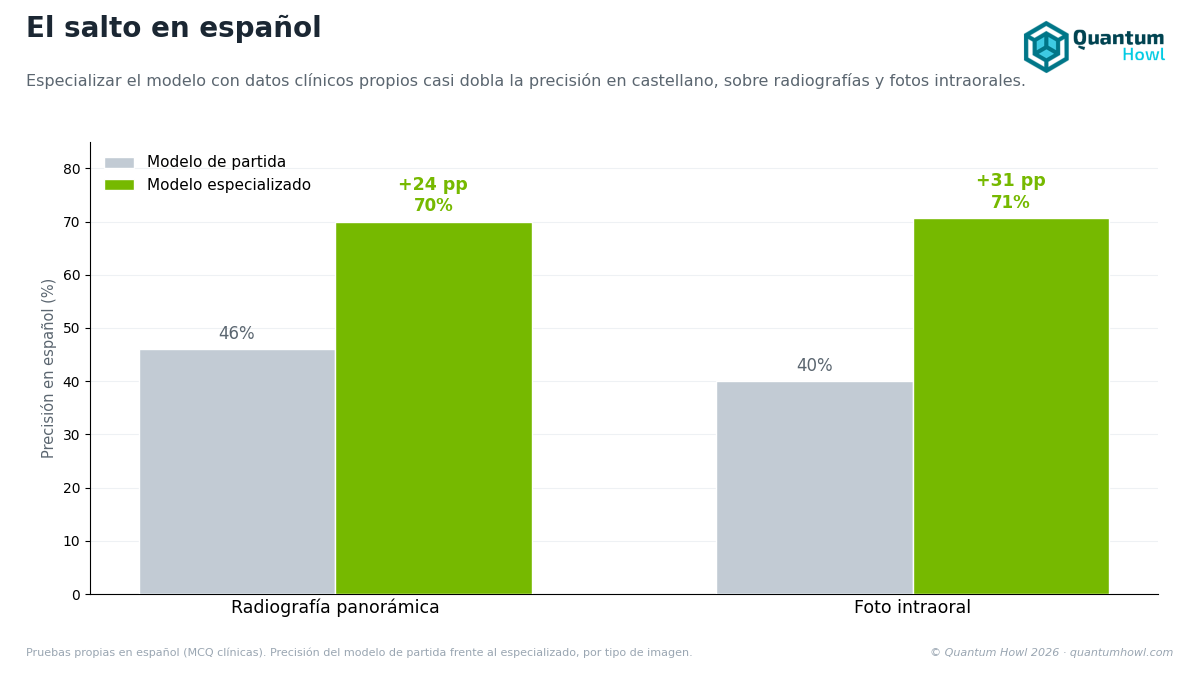
Resultados: probes ES
Panorámico ES (n=50, Wilson CI 95 %, MDE ≈ 14 pp)
| Modelo | Accuracy | CI 95 % | Δ vs base |
|---|---|---|---|
| Gemma 4 base | 46,00 % | [32,91, 59,62] | |
| Stage 3 v0 | 70,00 % | [56,25, 80,93] | +24,00 pp |
| Stage 3b v1 (+panorámico) | 64,00 % | [50,14, 75,86] | +18,00 pp |
| Stage 3b v2 (+intraoral) | 60,00 % | [46,18, 72,39] | +14,00 pp |
| Stage 3b v3 (combinado) | 62,00 % | [48,16, 74,20] | +16,00 pp |
Intraoral ES (n=75, MDE ≈ 11,4 pp)
| Modelo | Accuracy | Δ vs base |
|---|---|---|
| Gemma 4 base | ~40 % | |
| Stage 3 v0 | 70,67 % | +30,67 pp |
| Stage 3b v1 (+panorámico) | ~60 % | +20 pp |
| Stage 3b v2 (+intraoral) | ~64 % | +24 pp |
| Stage 3b v3 (combinado) | 68 % | +28 pp |
El McNemar pareado contra el base lo cierra direccionalmente: en intraoral ES los tres stages fine-tune son significativamente mejores que el base con p < 0,001; en panorámico ES solo v0 alcanza significancia formal, porque con n=50 el MDE queda en 14 pp, justo en el borde del delta de v1/v2/v3.
La pregunta que resuelve el control con Gemma 4 base
Antes de correr la evaluación había una hipótesis cómoda: «la paridad bilingüe del modelo viene del pre-entrenamiento multilingüe de Google sobre Gemma 4 31B, no necesariamente de nuestro training». Cómoda porque atribuiría el comportamiento en español al modelo base y dejaría el sprint mejor parado en inglés.
El resultado descarta esa hipótesis. Gemma 4 base obtiene 46,00 % panorámico ES y ~40 % intraoral ES, por encima del azar (25 % en preguntas de cuatro opciones): el pre-entrenamiento multilingüe sí le da vocabulario y razonamiento dental básico en español sin training específico. Pero nuestro fine-tune multiplica la accuracy por 1,5-1,8× en ambos probes, v0 SFT suma +24 pp en panorámico y +30,67 pp en intraoral sobre el base. La paridad ES↔EN que observamos en v3 no viene del pre-entrenamiento: viene del mix bilingüe (45/55 ES/EN en texto, 20/80 ES/EN en visión) que incluimos explícitamente en el corpus del Stage 3.
El hallazgo cross-language que no esperábamos
Al cruzar estos resultados con los de MMOral-Bench (en inglés) aparece un patrón que no estaba en ninguna hipótesis pre-registrada:
| Benchmark | Mejor stage | Ranking |
|---|---|---|
| MMOral-Bench cerrado EN (n=491) | v3 combinado | v3 > v2 > v0 > v1 |
| Panorámico ES (n=50) | v0 SFT | v0 > v1 > v3 > v2 |
| Intraoral ES (n=75) | v0 SFT | v0 > v2 > v3 > v1 |
v3 (combinado panorámico + intraoral) es el mejor en inglés. v0 (SFT puro) es el mejor en español. La explicación más plausible es que ambos son datasets en inglés: añadirlos al corpus del Stage 3b (v1/v2/v3) sesga el modelo hacia razonamiento en inglés y degrada ligeramente el dominio español que v0 manejaba mejor, al haberse entrenado con más proporción del corpus español original.
Eso cambia cómo pensamos el deploy. Si el cliente final opera en inglés (investigación, mercado USA), v3 es la elección defendible. Si opera en español (la clínica partner, el mercado español-latinoamericano), v0 es probablemente el deploy correcto, no v3. El sprint termina con dos candidatos validados para roles distintos, no con un «ganador único», y al cierre separamos los claims por idioma de forma explícita.
Caveats honestos
Conviene ser claro sobre lo que estos números no cierran. Las n son pequeñas (50 y 75), con Wilson CI 95 % anchos (±12-14 pp): el hallazgo de v0 > v3 en español tiene una magnitud (~8 pp) parecida al MDE, robusto direccionalmente, no cerrado estadísticamente. Hay además un único probe por modalidad: 50 panorámicas no representan toda la distribución panorámica, y sería deseable un n de 200+ y multi-fuente. La traducción introduce su propio riesgo: aunque el bucle de revisión reduce errores, queda una probabilidad residual de que algunas preguntas en español tengan ambigüedad terminológica que el inglés no tiene. Y persiste una anomalía menor: en intraoral, los ítems difíciles van mejor que los fáciles en español, lo que apunta a una deuda de calibración del probe que anotamos pero no cerramos en este sprint.
Estado al cerrar esta fase
- Dos probes propios bilingües operativos (panorámico-ES e intraoral-ES).
- 5 modelos evaluados, 1.250 preguntas en total.
- El control con Gemma 4 base confirma que la mejora en español viene del training, no del pre-entrenamiento.
- Hallazgo cross-language documentado: v0 ≠ v3 según el idioma.
- Backlog de mejoras bilingües abierto: MMOral-ES con n=491 (traducción paralela, coste de unos pocos dólares de API), probes ES con n > 200, y evaluación multimodal con imágenes clínicas reales.
Próximo capítulo: cómo validamos el modelo con odontólogas reales, en consulta, antes de fiarnos de cualquier número.



