

Chapter 7 of the Sprint DGX series (from Chapter 1). The bench that validates the trained VLM as a service that’s actually deployable.
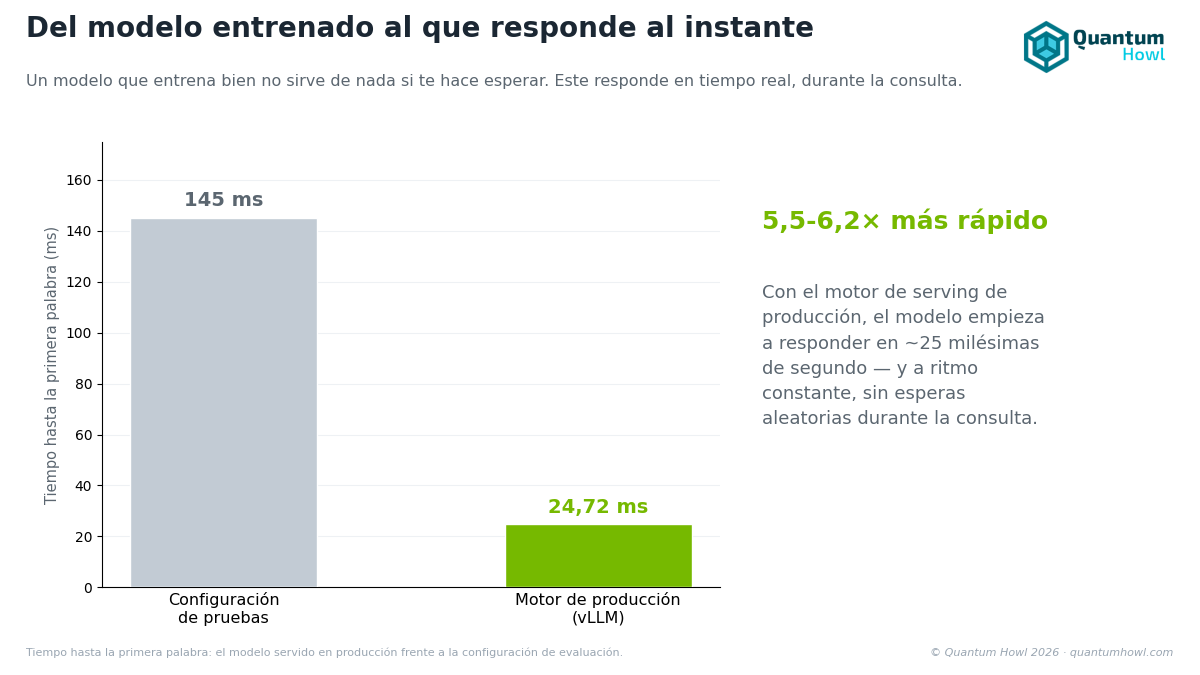
Training a model well and being able to serve it in the clinic are two different problems. A checkpoint that learns is just that: weights on disk. For a dentist to use it during a visit, it has to respond instantly and keep latency stable under load, even through usage spikes, without stumbling. This chapter is about the leap from the lab to the service: a sweep of fifteen vLLM configurations that brings time-to-first-token from the initial ~140 ms down to 24.72 ms, between 5.5 and 6.2 times faster, with a latency tail so narrow (under 1 ms between the median and the 99th percentile) that the wait is practically identical on every call. And, as an acid test, the model’s first look at a real radiograph through the deliverable’s serving runtime.
The gap between training and serving
The inference utility that ships with the training framework is optimized for evaluating checkpoints during training. It is not a service. It has three operational limitations for production:
- No KV cache shared across requests, every call starts from scratch.
- No dynamic batching, concurrent requests are serialized.
- No OpenAI-compatible API, it requires a custom Python client and doesn’t integrate with the SDK the rest of the product uses.
The initial numbers, measured with that utility, are honest but not useful for deploy:
| Baseline metric (training utility, H100 BF16) | Value |
|---|---|
| TTFT (time-to-first-token) | 136-153 ms |
| Throughput batch 1 | 12-14 tok/s |
| Throughput batch 4 | 38-40 tok/s |
| VRAM | Comfortable headroom, fits on the GPU |
To serve the VLM to a clinic you need a real serving runtime: dynamic batching, a reusable KV cache, a concurrent-request scheduler, and a stable API. We evaluated several options, and the one that fit Gemma 4 best, without sacrificing accuracy or adding complexity, was vLLM, which had just shipped support for the model.
vLLM with Day-0 support for Gemma 4
vLLM released official Day-0 support for the gemma4 model_type. That gave us exactly what we needed: a serving runtime that understood Gemma 4 31B from day one, without waiting for the rest of the ecosystem to catch up.
Installing vLLM in the sprint environment was clean: out-of-the-box, no build-from-source or downgrades, on the same torch and transformers we already had. Verified with a dry-run before running anything.
The serving architecture is deliberately simple: a single vLLM process serving the model in BF16 with tensor parallelism across two GPUs, with an OpenAI-compatible endpoint in front. Any client that speaks the OpenAI API connects directly. The QuantumHowl product’s client already speaks it by default, zero adaptation.
The bench sweep
The sweep covers four dimensions of the configuration space for production-representative load testing:
| Config type | Variants | n |
|---|---|---|
| Text-only | 3 prompt lengths {128, 512, 2048} × 4 concurrencies {1, 4, 16, 64} | 12 |
| Real conversation (ShareGPT) | batch 1 (100 conversations) + batch 4 (100 conversations) | 2 |
| Multimodal | vision input + text generation | 1 |
The full sweep ran in just over half an hour, with 14 of 15 configurations succeeding. The only one that failed was the multimodal one, due to an engine initialization conflict when running in parallel with the vllm serve already up, not a blocker: the multimodal smoke test was validated separately (next section).
The headline numbers
| Metric | vLLM BF16, H100 | Baseline (training utility) | Improvement |
|---|---|---|---|
| TTFT p50 | 24.72 ms | 136-153 ms | 5.5-6.2× |
| TTFT p99 | 25.4 ms | ||
| TTFT variance p50→p99 | < 1 ms | narrow tail | |
| Throughput batch 1, prompt 128 | 71.12 tok/s | 12-14 tok/s | 5.1-5.9× |
| Throughput batch 4, prompt 128 | 219 tok/s | 38-40 tok/s | 5.5-5.8× |
| Aggregate throughput batch 16, prompt 2048 | 549 tok/s | ||
| ShareGPT batch 1 (real conversation) | 100/100 success | ||
| ShareGPT batch 4 (real conversation) | 100/100 success |
The TTFT variance between p50 and p99 under 1 ms is the operational signature that really matters. A 5.5× improvement in median TTFT is lost if the latency tail is high, a clinical user who sometimes waits 25 ms and other times 250 ms has an unstable experience. A narrow tail indicates that vLLM’s scheduler keeps latency consistent under load, not just in the average case.
The 549 aggregate tok/s in batch 16 with long prompts scale throughput about 7.7× relative to batch 1 when dynamic batching is well tuned, and that’s what gives plenty of headroom to serve a clinic’s load with stable latency even at peak usage.
Multimodal smoke test: the model’s first look at a real radiograph
Qualitative validation on a real panoramic with annotated restorations:
| Metric | Value |
|---|---|
| Throughput | 42.4 tok/s batch 1 |
| Prompt tokens | 301 (256 vision + 45 text) |
| Generated tokens | 256 |
| End-to-end latency | 6.04 s |
| Response language | Spanish |
| Clinical coherence | Verified by hand |
The response correctly describes the restorations visible in the panoramic, identifies the relevant FDI regions, and maintains an appropriate clinical tone in Spanish. It’s not a deploy-grade evaluation (n=1, qualitative), but it confirms that the end-to-end pipeline, training (Chapter 4) → serving → multimodal inference, works on real data, not just on the benchmark.
The production path is chosen
vLLM with its OpenAI-compatible API is the deliverable’s serving runtime: fast, stable under load, and validated end-to-end on the trained model. The key piece is that the QuantumHowl product’s client already speaks that API natively, so serving the new VLM requires no architectural change, just pointing at a new endpoint.
Status at the close of this phase
- vLLM BF16 validated as primary serving.
- Bench sweep documented: 14 of 15 configurations succeeding.
- Headline numbers locked: TTFT p50 24.72 ms (5.5-6.2× better), 71.12 tok/s at batch 1, 549 tok/s aggregate, p50-p99 variance < 1 ms.
- Multimodal smoke test validated on a real panoramic.
- Production path defined: OpenAI-compatible REST, no architectural changes on the client.
Next chapter: why the DGX Spark matters as an on-prem, per-clinic deploy target, and how the trained VLM fits in its 128 GB of unified memory to run at full precision, inside the building, without any patient image leaving for the cloud.



