

Chapter 5 of the Sprint DGX series (from Chapter 1). Why you build your own benchmarks when the public one doesn’t cover your real distribution, and what happens when you do.
A model can ace an exam and still be useless for your clinic. The reference dental benchmark, MMOral-Bench, is well built, but it has two biases that matter to us: its 100 images are all panoramics, and in the clinic you also get periapicals and intraorals, and it’s entirely in English, while our clinics operate in Spanish. So instead of trusting a borrowed exam, we built our own: two in-house probes, panoramic and intraoral, translated into Spanish with clinical review. What we measured refutes a comfortable hypothesis (that Spanish “came out of the box” in Gemma 4) and uncovers a finding we didn’t expect: the best model in English isn’t the best in Spanish. The consequence is very practical for deciding which version to deploy in each market.
Why build our own probes
MMOral-Bench (NeurIPS ’25) is a serious benchmark, but it has three limitations from our point of view:
- Single modality: 100 images, all panoramic OPGs. The real product receives periapicals (common in day-to-day practice) and intraorals (direct mouth photos for follow-ups). Neither is in MMOral.
- Single language: the benchmark is in English. The real clinic operates in Spanish. The model’s ES↔EN parity is a hypothesis that has to be validated empirically, not assumed.
- Moderate n: 491 closed questions are enough for a paired McNemar between models, but the per-category breakdown suffers, many end up with n < 30, with wide and barely interpretable confidence intervals.
To cover that gap we designed two in-house probes:
| Probe | Source dataset | Modality | n questions |
|---|---|---|---|
| panoramic-ES | External panoramic dataset | Panoramic OPG | 50 |
| intraoral-ES | External intraoral dataset | Intraoral / periapical | 75 |
The questions are built on images with verified annotations from the original dataset and translated into Spanish with our own pipeline: a language model translates, a review loop goes over the clinical terminology, and an automatic filter checks against a Spanish dental glossary. The result is 125 parallel ES/EN questions, ready to evaluate any variant of the model.
The experimental block
The evaluation ran in four parallel processes of two GPUs each, with panoramic and intraoral in sequence within each process. In total, a few minutes of compute to evaluate 5 models × 2 probes × ~125 questions.
Models evaluated:
- Gemma 4 31B-IT base (no fine-tune, control)
- Stage 3 SFT v0 (the output of Chapter 4)
- Stage 3b v1 (+panoramic)
- Stage 3b v2 (+intraoral)
- Stage 3b v3 (combined panoramic + intraoral)
Results: ES probes
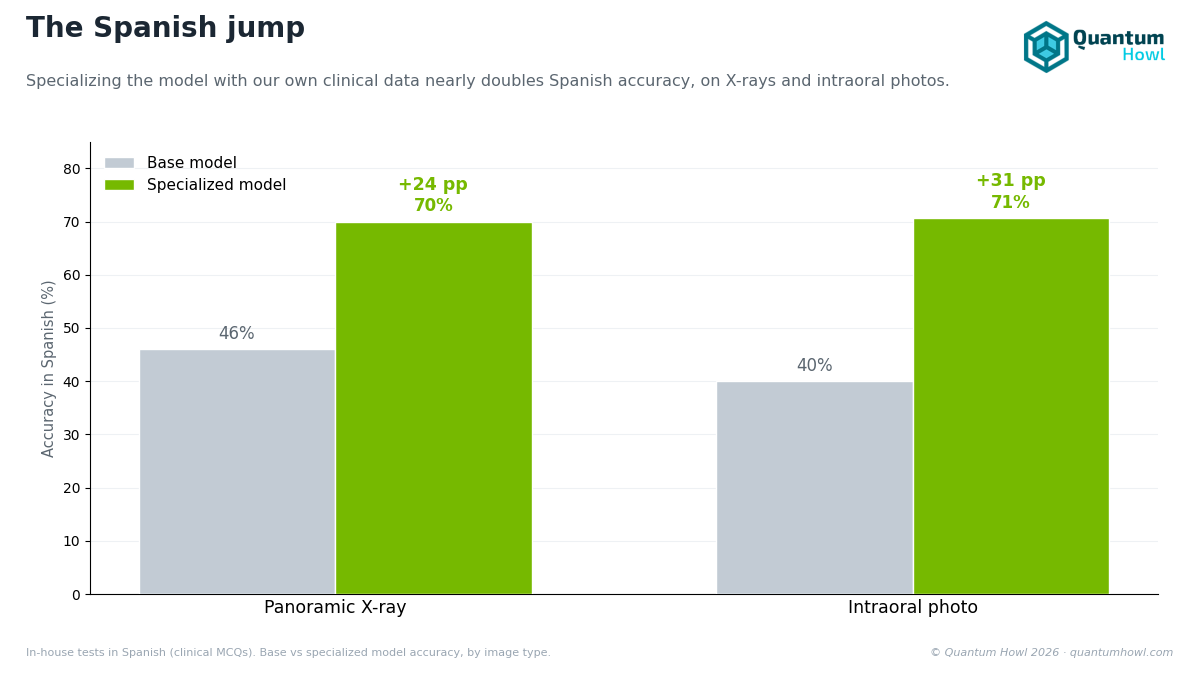
Panoramic ES (n=50, Wilson CI 95%, MDE ≈ 14 pp)
| Model | Accuracy | CI 95% | Δ vs base |
|---|---|---|---|
| Gemma 4 base | 46.00% | [32.91, 59.62] | |
| Stage 3 v0 | 70.00% | [56.25, 80.93] | +24.00 pp |
| Stage 3b v1 (+panoramic) | 64.00% | [50.14, 75.86] | +18.00 pp |
| Stage 3b v2 (+intraoral) | 60.00% | [46.18, 72.39] | +14.00 pp |
| Stage 3b v3 (combined) | 62.00% | [48.16, 74.20] | +16.00 pp |
Intraoral ES (n=75, MDE ≈ 11.4 pp)
| Model | Accuracy | Δ vs base |
|---|---|---|
| Gemma 4 base | ~40% | |
| Stage 3 v0 | 70.67% | +30.67 pp |
| Stage 3b v1 (+panoramic) | ~60% | +20 pp |
| Stage 3b v2 (+intraoral) | ~64% | +24 pp |
| Stage 3b v3 (combined) | 68% | +28 pp |
The paired McNemar against the base closes it directionally: on intraoral ES all three fine-tuned stages are significantly better than the base at p < 0.001; on panoramic ES only v0 reaches formal significance, because with n=50 the MDE sits at 14 pp, right on the edge of the v1/v2/v3 delta.
The question the Gemma 4 base control settles
Before running the evaluation there was a comfortable hypothesis: “the model’s bilingual parity comes from Google’s multilingual pre-training of Gemma 4 31B, not necessarily from our training”. Comfortable because it would attribute the Spanish behavior to the base model and leave the sprint looking stronger in English.
The result rules out that hypothesis. Gemma 4 base scores 46.00% panoramic ES and ~40% intraoral ES, above chance (25% on four-option questions): the multilingual pre-training does give it basic dental vocabulary and reasoning in Spanish without specific training. But our fine-tune multiplies accuracy by 1.5-1.8× on both probes, v0 SFT adds +24 pp on panoramic and +30.67 pp on intraoral over the base. The ES↔EN parity we observe in v3 doesn’t come from pre-training: it comes from the bilingual mix (45/55 ES/EN in text, 20/80 ES/EN in vision) that we explicitly included in the Stage 3 corpus.
The cross-language finding we didn’t expect
Cross-referencing these results with the MMOral-Bench ones (in English) reveals a pattern that wasn’t in any pre-registered hypothesis:
| Benchmark | Best stage | Ranking |
|---|---|---|
| MMOral-Bench closed EN (n=491) | v3 combined | v3 > v2 > v0 > v1 |
| Panoramic ES (n=50) | v0 SFT | v0 > v1 > v3 > v2 |
| Intraoral ES (n=75) | v0 SFT | v0 > v2 > v3 > v1 |
v3 (combined panoramic + intraoral) is the best in English. v0 (pure SFT) is the best in Spanish. The most plausible explanation is that both are English datasets: adding them to the Stage 3b corpus (v1/v2/v3) biases the model toward English reasoning and slightly degrades the Spanish domain that v0 handled better, having been trained with a higher proportion of the original Spanish corpus.
That changes how we think about deployment. If the end client operates in English (research, US market), v3 is the defensible choice. If it operates in Spanish (the partner clinic, the Spanish-Latin American market), v0 is probably the right deploy, not v3. The sprint ends with two validated candidates for distinct roles, not a “single winner”, and at the close we separate the claims by language explicitly.
Honest caveats
It’s worth being clear about what these numbers don’t settle. The n’s are small (50 and 75), with wide Wilson CI 95% (±12-14 pp): the v0 > v3 finding in Spanish has a magnitude (~8 pp) similar to the MDE, directionally robust, not statistically closed. There’s also a single probe per modality: 50 panoramics don’t represent the whole panoramic distribution, and an n of 200+ and multi-source would be desirable. Translation introduces its own risk: although the review loop reduces errors, there remains a residual probability that some Spanish questions carry terminological ambiguity that the English doesn’t. And a minor anomaly persists: in intraoral, the hard items do better than the easy ones in Spanish, which points to a probe calibration debt we note but don’t close in this sprint.
Status at the close of this phase
- Two in-house bilingual probes operational (panoramic-ES and intraoral-ES).
- 5 models evaluated, 1,250 questions in total.
- The Gemma 4 base control confirms that the improvement in Spanish comes from training, not from pre-training.
- Cross-language finding documented: v0 ≠ v3 depending on the language.
- Bilingual improvement backlog opened: MMOral-ES with n=491 (parallel translation, a few dollars of API cost), ES probes with n > 200, and multimodal evaluation with real clinical images.
Next chapter: how we validate the model with real dentists, in the clinic, before trusting any number.



