
Chapter 2 of the Sprint DGX series (start with Chapter 1). From signed pitch to first formal pivot email.
How a pre-registered benchmark on MMOral-Bench forced us to renegotiate the project’s base model with the NVIDIA Innovation Lab team in the first week of the sprint — and to honestly explain why we evaluated 3 of 11 candidate models, why the sizes were different (8B vs 11B vs 31B), and what trade-offs we accepted when choosing the winner.
The context: 60 days, an 8×H100 node, and a hypothesis that broke on Day 5
In April 2026 we kicked off a 60-day sprint under an NVIDIA Innovation Lab grant — a program we accessed as NVIDIA Inception members — with a DGX node of 8×H100s at our disposal. The goal: take the clinical vision model of Dental Brain to the next level through a four-stage multimodal fine-tuning pipeline.
The proposal we signed with NVIDIA assumed the base model would be LLaMA 3.2 11B Vision. It made sense on paper: open weights, broad community, we knew it inside out.
On Day 5 of the sprint we discovered, with data in hand, that this choice was a mistake. This is the post that tells how we found out, what we did about it, and why writing an email to NVIDIA explaining the change on the same day was the easiest decision of the sprint.
Day 4: the plan you sign before seeing the data
Anyone who has worked on model evaluation knows the most common trap is post-hoc justification of the choice you’d already made. The antidote is the pre-registered analysis plan: you write the rules of the game before rolling the dice, you sign them, and you publish them.
On Day 4 (April 11, 2026) we wrote exactly that. Three pieces:
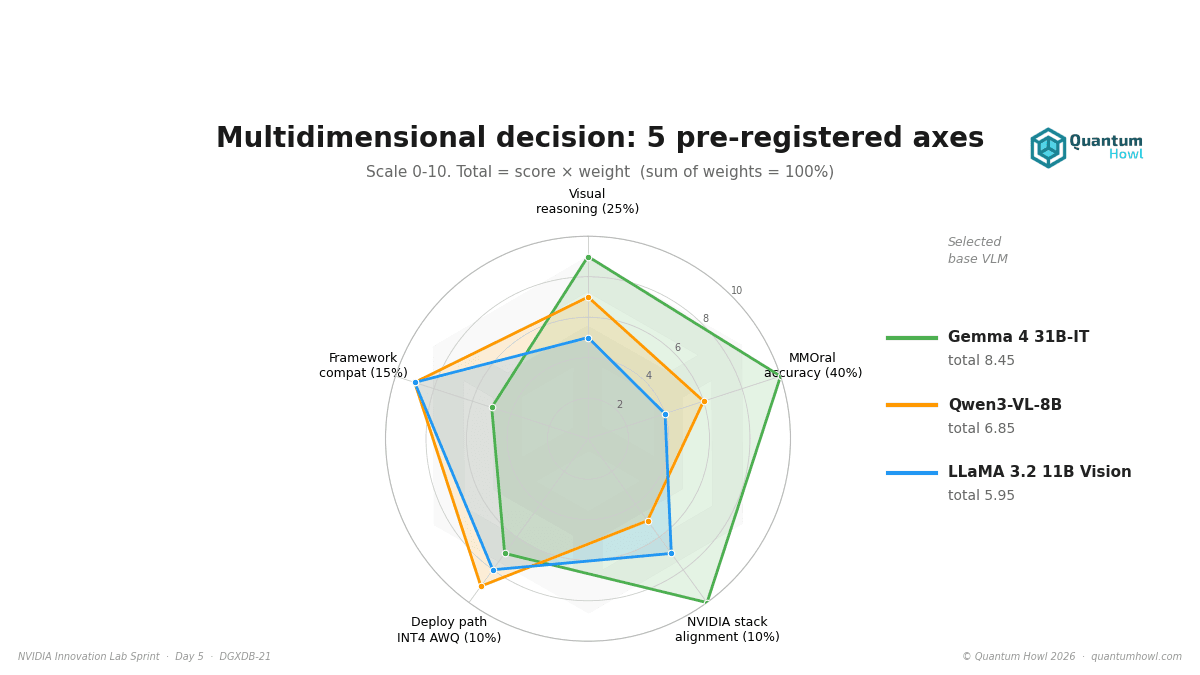
1. The decision weights, defined before seeing a single number
| Dimension evaluated | Weight in final decision |
|---|---|
| Overall accuracy on MMOral-Bench (closed-ended questions) | 40% |
| Qualitative dental visual reasoning | 25% |
| Compatibility with the pipeline’s training frameworks | 15% |
| Deployment viability in INT4 | 10% |
| Alignment with the NVIDIA stack (NIM, TensorRT-LLM) | 10% |
2. The statistics, also pre-registered
- Primary test: paired McNemar — the classic “for the same item, does model A get it right when B fails?” test.
- Confidence intervals: bootstrap with 1,000 resamples, fixed seed, 95% CI.
- Operational rule: two models are considered different only if their confidence intervals do not overlap.
3. A formal decision tree with a veto rule
If the difference in composite score between first and second place was below 0.05, there were explicit tiebreakers. And, above all, a veto rule: no model could be selected if it broke compatibility with the training frameworks without a documented alternative plan.
The plan was drafted, reviewed, and signed before executing anything. That gesture is what separates a benchmark from a confirmation-bias exercise.
Day 10: from a catalog of 11 candidates to 3 finalists
Before the benchmark we mapped the open-weight multimodal vision state of the art as of April 2026. Eleven plausible models: LLaMA 3.2 11B Vision (the pitch’s choice), Qwen3-VL-8B, Qwen3-VL-32B, Qwen2.5-VL-7B, Gemma 3 27B, Gemma 4 26B-A4B (MoE), Gemma 4 31B-IT, Nemotron Nano v2 VL 12B, InternVL3.5-8B, Pixtral 12B, Molmo 7B/72B, DeepSeek-VL2.
Of those 11, the initial plan was to benchmark 4: LLaMA 3.2 11B Vision (pitch commitment), Gemma 4 26B-A4B MoE (program recommendation), Qwen2.5-VL-7B (OralGPT-Omni reproducible baseline — the only model with a published fine-tuned dental recipe showing +24.7% on MMOral), and Qwen3-VL-8B (SOTA October 2025). Two optional: Nemotron Nano v2 VL 12B and InternVL3.5-8B.
What actually happened when we executed the benchmark that same week:
- Gemma 4 26B-A4B MoE: dropped pre-benchmark. Compatibility with our training framework was partial, the MoE experts didn’t take advantage of the Spark 128 GB deploy target’s VRAM budget, and the dense 31B-IT variant from the same April 2026 release was a cleaner option. We pivoted to Gemma 4 31B-IT as the Gemma 4 family representative.
- Qwen2.5-VL-7B: dropped from the final benchmark. It was duplicated by Qwen3-VL-8B (same team, next generation, alleged SOTA). The honest argument against this decision: it was the only model with a published reproducible dental recipe (OralGPT-Omni); it would have provided the only apples-vs-apples-by-recipe comparison point against existing literature. Trade-off accepted: we prioritized more recent models at the cost of losing that bibliographic anchor.
- Nemotron Nano v2 VL 12B: dropped from the benchmark. The Hybrid Mamba-Transformer architecture wasn’t a well-trodden path for QLoRA in our training framework, and the RADIOv2.5 encoder required a custom preprocessing pipeline. No time to integrate before Day 12, so we left it as a post-sprint candidate.
- InternVL3.5-8B: dropped from the benchmark. License derived from Qwen base on some sizes — complicated the commercial chain-of-custody for deploy in a client clinic (pure Apache 2.0 gave us less legal friction).
- The remaining 4 (Qwen3-VL-32B, Gemma 3 27B, Pixtral 12B, Molmo, DeepSeek-VL2): dropped due to higher VRAM (32B+ didn’t fit consumer-grade Spark tier) or pre-2025 release (not SOTA Q2 2026).
Result: 3 models in the final benchmark on Day 11–12, not 4. The asymmetry deserves explanation before reading the results table, because without this prior filter anyone could ask “and where is Qwen2.5-VL-7B with its published dental recipe?” — a legitimate question whose answer is trade-off, not oversight.
MMOral-Bench: the dental benchmark we used and the extraction problem we had to solve
MMOral-Bench (NeurIPS 2025) is a multimodal dental benchmark with 100 panoramic radiographs and 1,069 associated questions, split into two formats:
- 491 closed-ended questions with A/B/C/D multiple choice.
- 578 open-ended questions, evaluated by an LLM judge.
The first smoke test on Day 4 revealed an operational problem: VLM models don’t always answer with a letter. Sometimes they write three paragraphs of reasoning and bury the answer in the middle. The naive comparator (literal “A” against the output) marked very few correct cases, artificially depressing accuracy.
We built a multi-step answer extractor with five fallbacks that scans the text searching, in order:
- An isolated A-D letter at the end of the text (typical in chain-of-reasoning answers).
- An isolated A-D letter at the start.
- An exact match of one of the option texts inside the output.
- Fuzzy match by string similarity, threshold 0.4.
- If none of the above work, it counts as a failure. The item is never discarded. This matters: discarding “ambiguous” items is another classic way to cook results.
Every answer logs which method was used to extract it. Later this will be key to interpreting the results honestly.
For open-ended questions we used a binary LLM-as-judge: an independent LLM judge, temperature 0, fixed seed, and an immutable evaluation prompt. Total judge cost: USD 2.10, 32 minutes wall clock, zero API errors. (Yes, that’s the price of evaluating 578 answers with a frontier model. The era of the expensive benchmark is over.)
Day 5 results: three models, one surprise
We compared three VLM candidates with the same protocol:
| Model | Closed (n=491) | 95% CI | Open (judge, n=578) | Combined | Median latency |
|---|---|---|---|---|---|
| Gemma 4 31B-IT | 43.58% | [39.31 – 48.27] | 14.01% | 27.60% | 1,678 ms |
| Qwen3-VL-8B | 26.27% | [22.40 – 30.35] | 11.25% | 18.15% | 3,342 ms |
| LLaMA 3.2 11B Vision | 18.33% | [14.87 – 22.00] | 5.19% | 11.23% | 2,853 ms |
Gemma 4 31B-IT achieves 2.4× the accuracy of LLaMA 3.2 on closed-ended questions (43.58% vs 18.33%) over the same set. The bootstrap confidence intervals do not overlap between Gemma 4 and the other two models. The pre-registered rule (significant delta if CIs don’t touch) is comfortably satisfied.
And on open-ended questions, evaluated by an independent LLM judge, the ranking holds: Gemma 4 (14.01%) > Qwen3 (11.25%) > LLaMA 3.2 (5.19%).
The elephant in the room: three different sizes
Before moving on to paired McNemar, we have to acknowledge an uncomfortable detail. The three models are not the same size:
- Gemma 4 31B-IT — 31 billion parameters (dense)
- LLaMA 3.2 11B Vision — 11 billion parameters (8B text + 3B vision)
- Qwen3-VL-8B — 8 billion parameters (dense)
The winning model has nearly 3× the parameters of the original pitch model. A legitimate skeptic will say: “of course it wins, it’s 3× bigger.”
The honest answer is that the benchmark was NOT apples-vs-apples by parameter count. It was apples-vs-apples by product deploy target. The NVIDIA sprint was designed to deliver an on-premise deployable dental VLM running on DGX Spark 128 GB unified (Blackwell GB10, Q2 2026 release). The three compared models all fit on that hardware. The 70B+ tier of the catalog (LLaMA 3.2 90B Vision, Qwen3-VL-235B MoE) don’t fit on a single-GB10 Spark with serving headroom — they fell out of scrutiny precisely because they don’t fit the product decision.
Reframe the benchmark:
- Apples-vs-apples by params: “which architecture learns better per parameter?” — an academic question, with no immediate value to a client with a fixed hardware budget.
- Apples-vs-apples by deploy target: “of all the models that FIT on the hardware the client is going to buy, which performs best in their domain (dental, multimodal vision)?” — an operational question, aligned with the real use case.
Under the second framing, Gemma 4 31B-IT wins because it’s the biggest model that fits the deploy target, and because the extra parameters translate into measurable benchmark accuracy (43.58% vs 26.27% vs 18.33% MMOral closed). It’s not cheating: it’s the optimal product decision for the concrete scenario. If the client were a cloud provider with 1 TB of VRAM, the benchmark would have included the 70B+ tier and the decision might have been different. But the deploy target is an on-premise NVIDIA Spark workstation; we compare what we’re going to deploy.
One important nuance for the skeptical reader: the figure that measures the quality of the whole sprint isn’t the delta between model families on Day 5, but the delta of the same Gemma 4 31B-IT before and after the fine-tuning pipeline. That one is apples-vs-apples by parameters, architecture, family, and size — the only variable that changes is the training. That’s the metric used to evaluate what we did, and we’ll dedicate a specific analysis to it once the evaluation gates are signed off.
Paired McNemar: is the difference real, or is it noise?
This is where the pre-registered plan earns its keep. Paired McNemar looks, item by item, at how many times one model gets it right where the other fails:
| Comparison | n | Both correct | Only A correct | Only B correct | Both wrong | p-value |
|---|---|---|---|---|---|---|
| LLaMA 3.2 vs Gemma 4 | 491 | 42 | 48 | 172 | 229 | < 0.001 |
| LLaMA 3.2 vs Qwen3-VL | 491 | 46 | 44 | 83 | 318 | 0.000685 |
| Qwen3-VL vs Gemma 4 | 491 | 75 | 54 | 139 | 223 | < 0.001 |
Look at the “Only B correct” column: across the 491 paired LLaMA-vs-Gemma items, there are 48 cases where LLaMA wins and Gemma fails, versus 172 where Gemma wins and LLaMA fails. The asymmetry is huge and directionally clear.
All three comparisons are significant at p < 0.001. The null hypothesis — “the models are equivalent, this is noise” — is ruled out.
The asterisk that needs to be on the table: the output format problem
If we only showed the previous table we’d be telling half the story. Answer extraction isn’t equally easy for all models. The percentage of answers where no extraction method manages to identify a letter or an option differs sharply:
| Model | Letter at end | Fuzzy match | Extraction failed |
|---|---|---|---|
| Gemma 4 31B-IT | 0.8% | 3.0% | 13.4% |
| Qwen3-VL-8B | 1.2% | 17.3% | 41.1% |
| LLaMA 3.2 11B Vision | 1.0% | 13.9% | 51.5% |
LLaMA 3.2 fails extraction on more than half the items. That means part of the closed-ended gap could be output format quality, not clinical capability.
That’s where the control kicks in: open-ended questions are evaluated by an LLM judge that looks at the clinical content of the answer, not its format. And the judge confirms the same ranking (Gemma > Qwen3 > LLaMA), independently of the extractor.
The decision is robust to the caveat. And mentioning the caveat in the post, instead of sweeping it under the rug, is exactly the difference between a serious benchmark and an ad disguised as a benchmark.
The stone in the shoe: changing the model means changing the training framework
The benchmark also surfaced a technical constraint that wasn’t in the original plan. Plain summary:
- Gemma 4 31B is a new model and requires
a more recent version of transformers(introduced specifically to support themodel_type: gemma4that appears in the April 2026 release). - The previous training framework is pinned to an older version of
transformers. - They’re incompatible. If we pick Gemma 4, we have to change frameworks.
We formally evaluated five options:
| Option | Advantage | Cost |
|---|---|---|
| A. Migrate the whole pipeline to the new framework | Supports Gemma 4, unifies the stack, we already needed it for the final stage | Rewrite the configs of the first 3 stages |
| B. Keep the previous training framework in parallel with another environment | Zero migration cost in the short term | Two environments to maintain |
| C. Wait for the previous training framework to update | Zero effort | No known date — the sprint clock is ticking |
| D. Pick Qwen3-VL (second in the ranking) | Current stack works without changes | Sacrifice 17 percentage points of accuracy |
| E. Stay with LLaMA 3.2 (the original plan) | Zero political friction with NVIDIA | Sacrifice 25 percentage points |
We picked option A. The new framework was needed anyway for the last stage of the training pipeline, so extending its use to the rest of the process simplifies the stack rather than complicating it. The cost — rewriting the configs — is acceptable.
The email to NVIDIA, sent on Day 5
This is where the human part of the decision came in. The ego-driven obvious choice would have been: start training on Gemma 4 without saying a word, and if the final deliverable is good, no one asks. The correct choice was the opposite.
That same Day 5 we sent a formal email to the NVIDIA Innovation Lab team. No defense, no apologies, no asking permission: simply explaining what we’d found, what we were going to do, and why. An excerpt of the body (verbatim, as sent):
“We’re pivoting our primary VLM from LLaMA 3.2 11B Vision to Gemma 4 31B-IT, based on benchmark results from our first week. We wanted to share the reasoning transparently since it deviates from the original pitch. […] Gemma 4 outperforms LLaMA 3.2 by 2.4× on closed-ended dental questions — a gap we believe will compound through our 4-stage fine-tuning pipeline. […] We see this as the kind of decision the Innovation Lab program is designed to enable — the compute access let us benchmark rigorously in Week 1 instead of committing to a model based on published benchmarks alone.”
The email included the accuracy table, the McNemar result, the framework-change justification, and an explicit list of “what doesn’t change” (the four stages of the pipeline, the production agents, the calendar, the 8×H100 instance).
The tone is not defensive: the change is presented as exactly the kind of decision the Innovation Lab program is designed to enable. The grant’s compute access let us run a rigorous benchmark in the first week, instead of committing to a model based on third-party published benchmarks. That’s the grant working as it should.
Accepted trade-offs: the cost of switching from LLaMA 3.2 to Gemma 4
The sprint’s base model is now fixed at Gemma 4 31B-IT (Apache 2.0). Pre-registered composite score: 8.45 against 6.85 for Qwen3-VL and 5.95 for LLaMA 3.2. We accept four documented trade-offs, without dressing them up:
- Minimum deploy tier rises from 16 GB → 24 GB INT4 AWQ. Any clinic that hoped to run inference on a 16 GB RTX 4080/4090 is out of the MVP. The hardware niche narrows to RTX 4090/5090 24 GB and up. The good news: the real product target is DGX Spark with 128 GB of unified memory, and Gemma 4 31B fits comfortably there.
- Training stack changes: we switch training framework across all 4 pipeline stages. Forced by the
a more recent version of transformersconstraint that Gemma 4 introduced in April 2026 and that the previous framework didn’t support in its current release. Configs rewritten, JSONL datasets identical. - Per-GPU VRAM during training rises from ~28 GB/GPU (LLaMA 3.2 11B LoRA) to ~70 GB/GPU (Gemma 4 31B LoRA bf16). Fits on 8×H100 80 GB but with smaller batch size and more recompute.
- The Innovation Lab pitch committed to LLaMA 3.2 11B Vision. The change required formal notification with benchmark-based justification before kicking off the first training stage. We wrote it the same day.
Apache 2.0 license, no commercial restrictions for clinical deployment. A hard requirement from the start and met.
That’s the technical transparency that actually moves a project forward: naming the costs without makeup, committing to a new deliverable (Gemma 4 fine-tuned with the four-stage pipeline) with the real figure, and leaving the decision auditable for anyone who wants to review it.
The lesson, no moralizing
The sprint was designed to train a model for 60 days. What we discovered on Day 5 is that this design had a vulnerability before it even started: we hadn’t empirically validated the base model choice. We took it for granted.
Spending the first week on a rigorous benchmark, with a pre-registered plan, before touching a single line of fine-tuning, was the best investment of the whole sprint. We would have thrown away three weeks training on the wrong model.
And writing the email to NVIDIA the same day — instead of hiding the change or justifying it later with final results — turned out to be the easiest decision to make once the numbers were clear. Transparency, counterintuitively, is cheaper than silence.
Next chapter: we have a sizeable anonymized DICOM corpus ready to upload to the training node, but GDPR Art. 9 (special category: health data) demands data-destruction guarantees that no cloud provider documents by default. Two parallel email threads asking for a Certificate of Destruction, and the day legal nearly stopped the ML.



